
CNN实现MNIST数据集准确率99.35%
徐静
该样例是我在联信集团数据分析师深度学习培训中所举的样例,使用Keras实现。在没有TPU或GPU的前提下,使用个人CPU训练CNN,并使MNIST数据集的测试集的准确率达到99.35%,官网上目前最厉害的模型的准确率好像是99.77%,离大牛还差好远的距离。。。。。。
- 使用Keras (下一个例子纯用tensorflow)
- 使用SELU激活函数,这是Sepp Hochreiter最新发表在arXiv上的激活函数,Sepp是当年和Jürgen Schmidhuber 一起发明 LSTM 的神级人物(不过效果不好,还是用relu吧)
- Batch normalization 的 batch 是批数据, 把数据分成小批小批进行随机梯度下降. 而且在每批数据进行前向传递 forward propagation 的时候, 对每一层都进行 normalization 的处理。 优点是可以避免数据对激活函数的饱和从而收敛到更好的结果,并且能减少训练时长。
- RMSprop 是 Geoff Hinton 提出的一种以梯度的平方来自适应调节学习率的优化方法(感觉不如adadelt,效果还不错,这些优化方法宁新会具体讲)
- 交叉熵计算原理是 $−[ylna+(1−y)ln(1−a)]$ 。不选择MSE的原因是,使用MSE在Y取较大值时,权重和偏置的更新速度会很慢,而用交叉熵作为损失函数可以克服这个问题
import numpy as np
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense,Activation,Conv2D
from keras.layers import MaxPool2D,Flatten,Dropout,ZeroPadding2D,BatchNormalization
from keras.utils import np_utils
import keras
from keras.models import save_model,load_model
from keras.models import Model
Using TensorFlow backend.
from keras.datasets import mnist
batch_size = 64
num_classes = 10
epochs = 12
# input image dimensions
img_rows, img_cols = 28, 28
# the data, shuffled and split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
n_filters = 32
pool_size = (2,2)
x_train shape: (60000, 28, 28)
60000 train samples
10000 test samples
#设定相关参数
cnn_net = Sequential()
cnn_net.add(Conv2D(32,kernel_size=(3,3),strides=(1,1),input_shape=(28,28,1)))
cnn_net.add(Activation('relu'))
cnn_net.add(MaxPool2D(pool_size=pool_size))
cnn_net.add(ZeroPadding2D((1,1)))
cnn_net.add(Conv2D(48,kernel_size=(3,3)))
cnn_net.add(Activation('relu'))
cnn_net.add(BatchNormalization(epsilon=1e-6,axis=1))
cnn_net.add(MaxPool2D(pool_size=pool_size))
cnn_net.add(ZeroPadding2D((1,1)))
cnn_net.add(Conv2D(64,kernel_size=(2,2)))
cnn_net.add(Activation('relu'))
cnn_net.add(BatchNormalization(epsilon=1e-6,axis=1))
cnn_net.add(MaxPool2D(pool_size = pool_size))
cnn_net.add(Dropout(0.25))
cnn_net.add(Flatten())
cnn_net.add(Dense(3168))
cnn_net.add(Activation('relu'))
cnn_net.add(Dense(10))
cnn_net.add(Activation('softmax'))
#查看网络结构
cnn_net.summary()
from keras.utils.vis_utils import plot_model,model_to_dot
from IPython.display import Image,SVG
SVG(model_to_dot(cnn_net).create(prog='dot',format='svg'))
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
activation_1 (Activation) (None, 26, 26, 32) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 13, 13, 32) 0
_________________________________________________________________
zero_padding2d_1 (ZeroPaddin (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 13, 13, 48) 13872
_________________________________________________________________
activation_2 (Activation) (None, 13, 13, 48) 0
_________________________________________________________________
batch_normalization_1 (Batch (None, 13, 13, 48) 52
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 6, 6, 48) 0
_________________________________________________________________
zero_padding2d_2 (ZeroPaddin (None, 8, 8, 48) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 7, 7, 64) 12352
_________________________________________________________________
activation_3 (Activation) (None, 7, 7, 64) 0
_________________________________________________________________
batch_normalization_2 (Batch (None, 7, 7, 64) 28
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 3, 3, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 3, 3, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 576) 0
_________________________________________________________________
dense_1 (Dense) (None, 3168) 1827936
_________________________________________________________________
activation_4 (Activation) (None, 3168) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 31690
_________________________________________________________________
activation_5 (Activation) (None, 10) 0
=================================================================
Total params: 1,886,250
Trainable params: 1,886,210
Non-trainable params: 40
_________________________________________________________________

#模型训练
cnn_net.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
cnn_net.fit(x_train,y_train,batch_size=batch_size,epochs=50,verbose=1,
validation_split=0.2)
cnn_net.save('cnn_net_model_eg1.h5')
Train on 48000 samples, validate on 12000 samples
Epoch 1/50
48000/48000 [==============================] - 172s - loss: 0.0094
- acc: 0.9968 - val_loss: 0.0313 -val_acc:0.9919
- ETA: 127s - loss: 0.5465 - acc: 0.8354
Epoch 12/50
48000/48000 [==============================] - 178s - loss: 0.0025
- acc: 0.9991 - val_loss: 0.0373 - val_acc: 0.9923
- ETA: 132s - loss: 0.0035 - acc: 0.9983
- ETA: 94s - loss: 0.0035 - acc: 0.9988
- ETA: 107s - loss: 0.0024 - acc: 0.9991
Epoch 29/50
48000/48000 [==============================] - 168s - loss: 0.0014
- acc: 0.9996 - val_loss: 0.0422 - val_acc: 0.9928
Epoch 38/50
42496/48000 [=========================>....] - ETA: 17s - loss: 0.0014
- acc: 0.9995998 6
#上述过程在我的个人PC电脑上跑了4个小时,我都崩溃了,
#我把训练好的模型保存了下来,下次使用直接加载
Model = load_model('cnn_net_model_eg1.h5')
score = Model.evaluate(x_test, y_test, batch_size=128)
9984/10000 [============================>.] - ETA: 0s
score
#这个列表里放的什么东西?我们可以通过metrics_names查看这俩货的确切含义
[0.037825437654955565, 0.99350000000000005]
Model.metrics_names
#奥原来一个叫损失,一个叫准确率(测试数据的准确率,发现比训练数据的准去率差一点点,
#有点过拟合,不过没关系,可以用宁新的正则化去解决这些问题)
['loss', 'acc']
print(str(Model.metrics_names[0])+':'+str(score[0])+'\n'+
str(Model.metrics_names[1])+':'+str(score[1]))
loss:0.037825437655
acc:0.9935
pred = Model.predict(x_test,batch_size=128)
#这个预测是softmax给的说以是概率,职能自己手动转化成label
test_pred = np.argmax(pred,axis=1)
y_test1 = np.argmax(y_test,axis=1)
#plot
import matplotlib.pyplot as plt
%matplotlib inline
actuals = y_test1[0:6]
predictions = test_pred[0:6]
images = np.squeeze(x_test[0:6])
Nrows = 2
Ncols = 3
for i in range(6):
plt.subplot(Nrows, Ncols, i+1)
plt.imshow(np.reshape(images[i], [28,28]), cmap='Greys_r')
plt.title('Actual: ' + str(actuals[i]) + ' Pred: ' + str(predictions[i]),
fontsize=10)
frame = plt.gca()
frame.axes.get_xaxis().set_visible(False)
frame.axes.get_yaxis().set_visible(False)
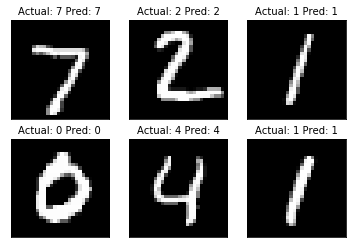
ok!!简单的网络就可以实现谦谦在前馈神经网络中的手写字识别,并把正确率提高到99.35%
