
TensorFlow分布式并行(结构篇)
1. 分布式TensorFlow原理
a.单机多卡和分布式
单机多卡是指单台服务器有多块GPU,这种情况下就是我们在上一节说的多GPU并行,其过程我们重复描述如下:
- 假设有4块GPU,在单机多卡中一次处理4个批次的数据,每个GPU处理一个批次的数据计算。
- 变量,也就是参数,保存在CPU上,数据由CPU分发给4个GPU,在GPU上完成计算,得到每个批次要更新的梯度。
- 在GPU上收集完4个GPU上更新的梯度,计算一下平均梯度,然后更新参数。
- 继续2和3步,循环这个过程
分布式是指训练在多个工作节点(worker)上,工作节点是指实现计算的一个单元,如果计算服务器是单卡,一般就是指的这台服务器;如果计算服务器是多卡,还可以根据多个GPU划分多个工作节点。当数据量达到超过一台机器的处理能力时,必须使用分布式。
分布式TensorFlow的底层通信是gRPC(google remote proceduce call)。gRPC是google开源的一个高性能,跨语言的RPC框架。RPC协议,即远程调用协议,是指通过网络从远程计算机程序上请求服务。也就是说,假设记载本机上执行了一段代码num=add(a,b),他被调用后得到一个返回结果,你感觉这段代码是在本机执行的,但实际上的add方法是将参数打包发送给远程服务器,由远程服务器运行add方法,将返回的结果在打包发送给本机客户端。
b.分布式部署的方式
- 单工作节点部署
单工作节点部署时在每台服务器上运行一个工作节点,假设服务器有4个GPU,一个工作节点可以访问4块GPU,这时候需要在代码中通过tf.device()指定运行操作的设备。
- 多工作节点部署
多工作节点是指一台服务器上可以运行多个工作节点。部署有一下两种方法。
(1).设置CUDA_VISIBLE_DEVICES环境变量,限制各个工作节点智能看到一个GPU,启动进程时添加环境变量即可。例如每个工作节点只能访问一个GPU,在代码中不需要额外的反应。
(2).使用tf.device()指定使用特定的GPU
多工作节点的部署的优势是代码简单,提高GPU使用率。多工作节点的部署的劣势是工作节点间如果需要通信就不能利用本地GPU的优势,而且部署时需要 部署多个工作节点。
2.分布式架构
主要有客户端和服务端组成,服务端有包括主节点和工作节点两者组成。我们需要关注客户端,主节点和工作节点这三者见的关系和他们的交互过程。
a.客户端、主节点和工作节点的关系
简单的说TF中,客户端通过会话来联系主节点,实际的工作交由工作节点实现。每个工作节点占用一台设备(TF具体计算的硬件抽象,即CPU和GPU)。单击模式下,客户端,主节点和工作节点都在同一台服务器上;在分布式模式下,他们可以位于不同的服务器。
- 客户端
客户端用于建立TF计算图,并建立与集群交互的会话层。因此代码中只要包含Session()就是客户端,一个客户端可以同时与多个服务端相连,同时一个服务端也可以同时与多个客户端相连。
- 服务端
服务端是一个运行了tf.train.Server实例的进程。是TensorFlow执行任务的集群(cluster)的一部分并由主节点服务(master service 也叫主节点)和工作节点服务(worker service 也叫工作节点)之分,运行中有一个主节点进程和数个工作节点进程组成,主节点进程和工作节点进程之间通过接口通信。单机多卡和分布式都是这种结构,因此只需要修改他们之间的接口通信方式就可以切换单机多卡和分布式切换。
- 主节点服务
主节点服务实现了tensorflow::Session接口,通过RPC服务程序来远程连接工作节点,与工作节点的服务进程中的工作任务进行通信。在TF服务端,一般是task_index为0的作业job
- 工作节点服务
工作节点服务是worker_service.proto接口的实现,使用本地设备对部分图进行计算,在TensorFlow服务端中,所有工作节点都包含工作节点的服务逻辑,每个工作节点负责管理一个或多个设备。工作节点也可以是不同端口的不同进程,或者多台服务器上的多个进程
在运行TF分布式时,我们首先要创建一个TF集群(cluster)对象,集群是TF分布式执行的任务集,有一个或多个作业(job)组成,而每个作业又有一个或多个具有相同目的的任务(task)组成。每个任务一帮有一个进程来执行。由此可知 作业是任务的集合,集群是作业的集合。
在分布式机器学习框架中,一般把作业划分为参数作业(parameater job)和工作节点zuoye(worker job),参数作业运行的服务器称为参数服务器(PS)负责管理参数的存储和更新;工作节点的作业负责管理无状态且主要从事计算的任务。
当模型越来越大,模型的参数越来越多,多到一台机器的性能不能够完成对模型参数的更新时,就需要把参数分开放到不同的机器去存储和更新,参数服务器可以是多台组成的集群,这就类似于分布式的存储架构,设计数据的同步和一致性。
因此参数的存储和更新是在参数作业中进行的,模型的计算是在工作节点作业中进行中。
3.分布式模式
在训练一个模型的时候那些部分可以分开,放在不同的机器上运行,这里类似于多GPU并行提供了两种模式:数据并行和模型并行。
- 数据并行
CPU负责梯度平均和参数更新,GPU1和GPU2主要负责训练模型副本。这里称作模型副本是因为他们都是基于训练样本的子集训练得到的,模型之间具有一定的独立性。
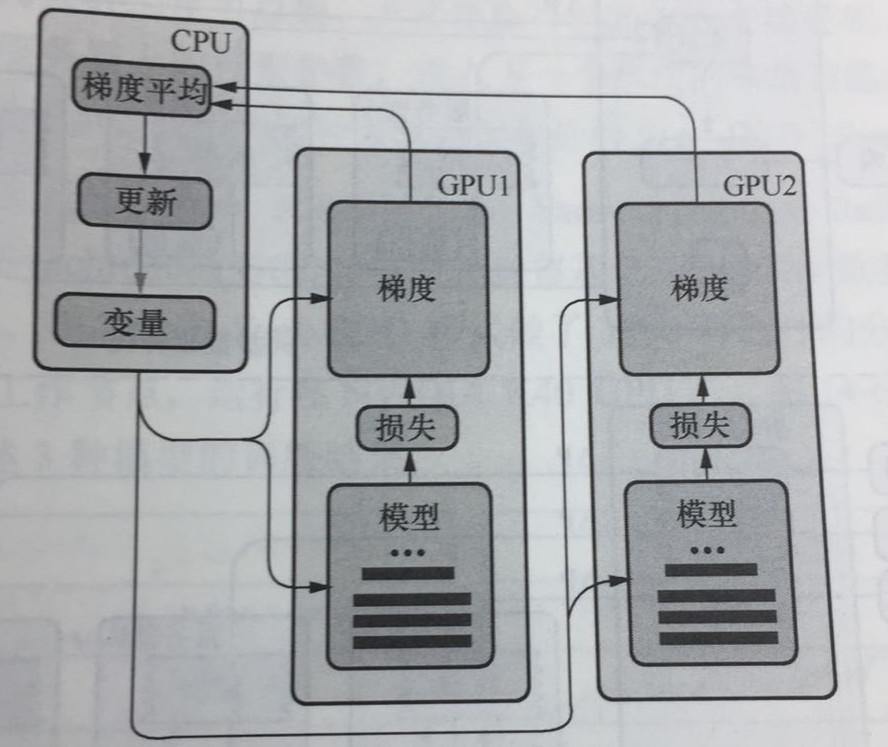
具体的训练步骤:
(1). 在GPU1和GPU2上分别定义模型网络结构。
(2). 对于单个GPU,分别从数据管道读取不同的数据块,然后进行前向传播,计算出损失,在计算当前变量的梯度。
(3). 把所有 GPU计算的梯度转移到CPU上,先进性 梯度求平均操作,然后进行模型变量的更新。
(4)重复(1)-(3)知道你模型变量收敛为止。
数据并行的目的是提高SGD的效率。
- 同步更新和异步更新
分布式随机梯度下降法是指,模型参数可以分布式的存储在不同的参数服务器上,工作节点可以并行的训练数据并且能够和参数服务器通信获取模型参数。更新参数也分为同步和异步即同步随机梯度下降和异步随机梯度下降,如下图所示:
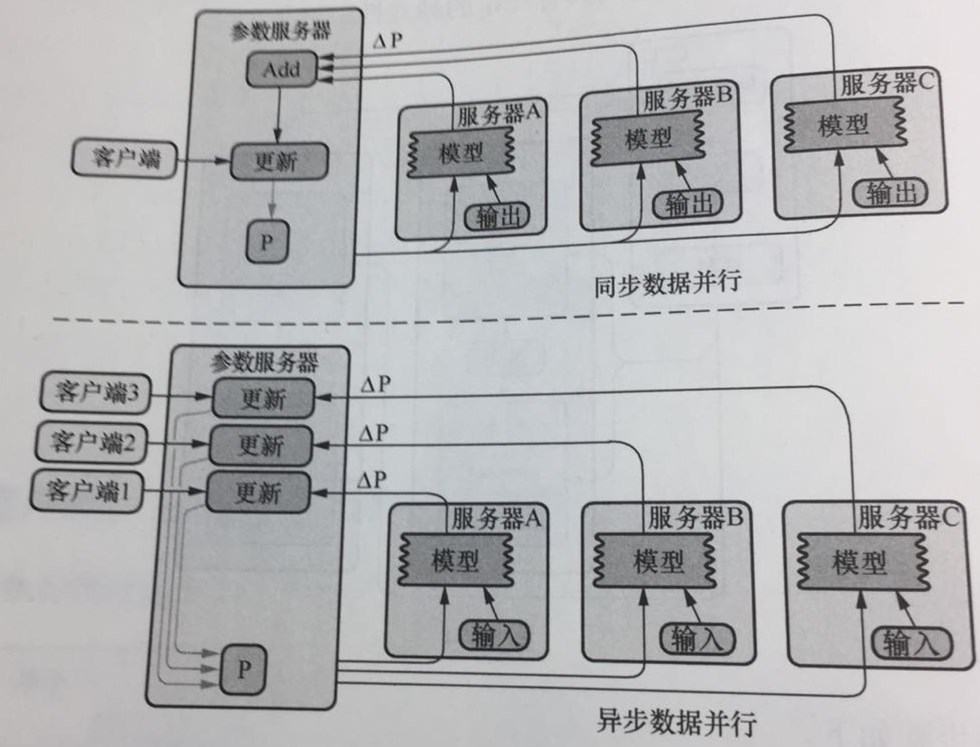
同步随机梯度下降法:在训练时每个节点上的工作任务需要读入共享参数,执行并行的梯度计算,同步需要等待所有工作节点把局部的梯度算好,然后将所有共享参数合并,累加,再一次性更新到模型的参数;下一个批次中,所有工作节点拿到模型更新后的参数在进行训练。
异步随机梯度下降法的含义是每个工作节点上的任务独立计算局部梯度,并异步更新到模型的参数中,不需要执行协调和等待操作。这种方案的优势是性能不存在瓶颈,劣势是每个工作节点计算的梯度值发挥到参数服务器会有参数更新的冲突,一定程度上会影响算法的收敛速度,在损失下降的过程中抖动较大。
在数据量小,各个节点的计算能力比较均衡的情况下,推荐使用同步模式;在数据量很大,各个机器的计算性能参差不齐的情况下,推荐使用异步模式,一般数据量足够大的情况休啊异步更新的效果会更好。
为了解决有些工作节点计算比较慢的问题,可以使用多一些的工作节点。例如让工作节点变为:n+n*5%,n为集群工作节点数。异步更新可以设定为在接受到n个工作节点的参数后,可以直接更新参数服务器上的模型参数,进入下一个批次的模型训练,计算比较慢的节点上训练出来的参数直接被丢弃,称这种方法为带备份的Sync-SGD.
- 模型并行
可以对模型进行切分,让模型的不同部分执行在不同的设备上,这样一个批次的样本可以在不同设备上同时执行,为了充分利用同一台设备的计算能力,TF会尽量让相邻的计算在同一台设备上完成来节省网络开销。
4.分布式API
创建集群的方法是为每个任务(task)启动一个服务(工作节点服务或者主节点服务)。这些任务可以分布在不同的机器上,也可以同一台机器启动多个任务,使用不同的GPU来运行。每个任务会完成一下工作。
(1).创建一个tf.train.ClusterSpec,用于对集群中的所有任务进行描述,该描述对所有任务应该是相同的。
(2).创建一个tf.train.Server,用于创建一个服务,并运行相应作业上的计算任务。
TensorFlow的分布式开发API的主要包括以下几个:
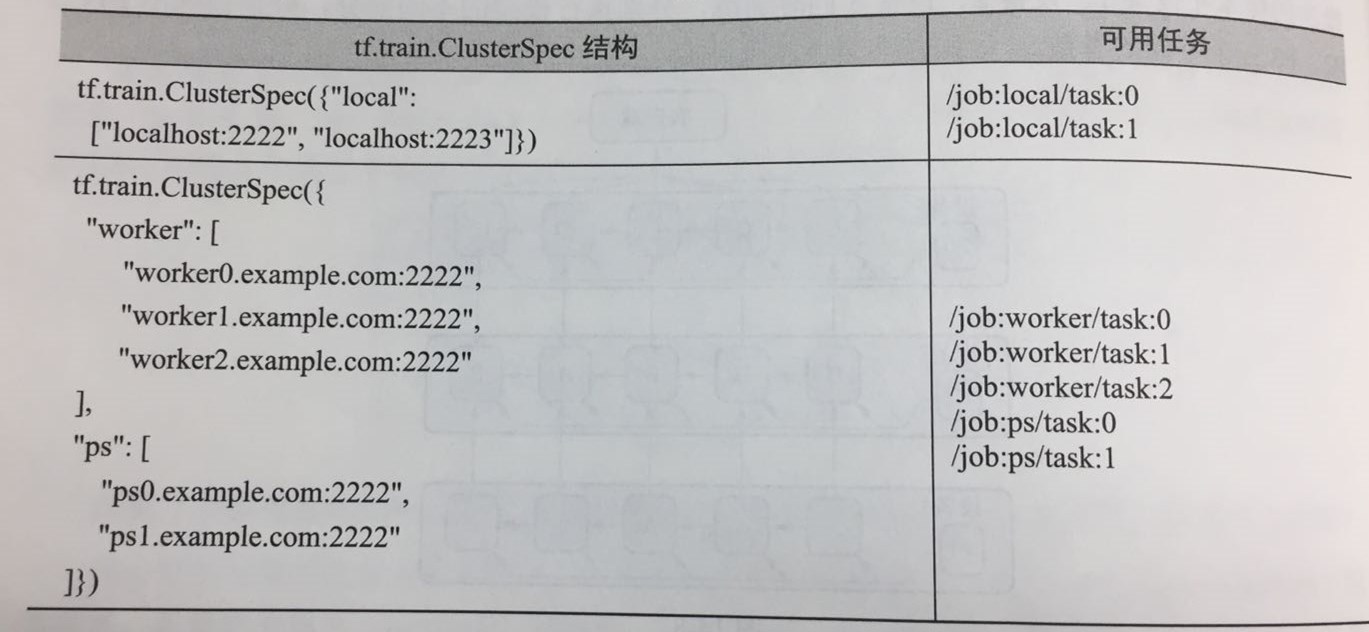
(1).tf.train.ClusterSpec({“ps”:ps_hosts,”worker”:worker_hosts})。创建TensorFlow集群描述信息,其中ps和worker为作业名称,ps_hosts和worker_hosts为该作业的任务所在节点的地址信息,下图给出了两个示例,tf.train.ClusterSpec的传入参数是作业和任务之间的关系映射,该映射关系中的任务是通过IP地址和端口号表示。
(2).tf.train.Server(cluster,job_name,task_index)。创建一个服务(主节点服务或工作节点服务),用于运行相应作业上的计算任务,运行的任务在task_index指定的机器上启动,例如在本地2222和2223两个端口配置不同服务。
# 在任务0
cluster = tf.train.ClusterSpec({"local":["localhost:2222","localhost:2223"]})
server = tf.train.Server(cluster,job_name="local",task_index=0)
# 在任务1
cluster = tf.train.ClusterSpec({"local":["localhost:2222","localhost:2223"]})
server = tf.train.Server(cluster,job_name="local",task_index=0)
但这种做法需要手动配置节点,无法实现动态的扩容。当集群规模比较大时,就需要自动化的管理节点,监控节点的工具,如集群管理工具Kubernetes。
(3).tf.device(device_name_of_function)。设定在指定的设备上执行张量运算,指定代码运行在CPU和GPU上,示例如下:
# 指定在task0所有的机器上执行Tensor的操作运算
with tf.device("/job:ps/task:0"):
weights_1 = tf.Variable(...)
biases_1 = tf.Variable(...)
5.分布式训练代码框架
# 第1步:命令行参数解析,获取集群的信息ps_hosts和worker_hosts
# 以及当前节点的角色信息job_name和task_index
tf.app.flags.DEFINE_string("ps_hosts","","Comma-separatedlistof hostname:portpairs")
tf.app.flags.DEFINE_string("worker_hosts","","Comma-separatedlistof hostname:portpairs")
tf.app.flags.DEFINE_string("job_name","","oneof'ps','worker'")
tf.app.flags.DEFINE_integer("task_index",0,"Index of task within the job")
FLAGS = tf.app.flags.FLAGS
ps_hosts = FLAGS.ps_host.split(",")
worker_host = FLAGS.worker_hosts(",")
# 第2步: 创建当前任务节点的服务器
cluster = tf.train.ClusterSpec({"ps":ps_hosts,"worker":worker_hosts})
server = tf.train.Server(cluster,job_name=FLAGS.job_name,task_index=FLAGS.task_index)
# 第3步:如果当前节点是参数服务器,则调用server.join()无休止等待,如果是工作节点,则执行第4步
if FLAGS.job_name == "ps":
server.join()
# 第4步:构建要训练的模型,构建计算图
elif FLAGS.job_name == "worker":
# build tensorflow graph model
# 第5步: 创建tf.train.Supervisor来管理模型的训练过程
# 创建一个supervisor来监督训练过程
sv = tf.train.Supervisor(is_chief=(FLAGS.task_index==0),logdir="/tmp/train_logs")
# supervisor负责会话初始化和从检查点恢复模型
sess = sv.prepare_or_wait_for_session(server.target)
# 开始循环到supervisor停止
while not sv.should_stop():
# 模型训练
