- 1.What is TensorRT
- 2.How Do I Get TensorRT?
- 3.Working with TensorRT Using the Python API
- 4.An Object Detection Model: YOLO v3 with TensorRT (Example 1)
- 5.A Classification Model: ResNet50 with TensorRT (Example 2)
1. What is TensorRT
1. What is TensorRT
TensorRT™的核心是一个C ++库,可以促进在NVIDIA图形处理单元(GPU)上的高性能推断。它旨在与TensorFlow,Caffe,PyTorch,MXNet等深度学习训练框架以互补的方式工作。它专注于在GPU上快速有效地运行已经训练过的网络,以便生成结果(在各个地方称为评分、检测、回归或推理的过程)。
一些训练框架(如TensorFlow)集成了TensorRT(比如TensorFlow 1.9.0集成了TensorRT 4),因此可用于加速框架内的推理。但是,TensorRT可以用作用户应用程序中的库。它包括用于从Caffe、ONNX或TensorFlow导入现有模型的解析器,以及用于以编程方式构建模型的C ++和Python API。
TensorRT通过组合层和优化内核选择来优化网络,从而改善延迟、吞吐量、功效和内存消耗。如果应用程序指定,它还将优化网络以更低的精度运行,进一步提高性能并降低内存需求。
TensorRT
被定义为高性能推理优化器和部件运行时引擎的一部分。它可以接受在这些流行框架上训练的神经网络,优化神经网络计算,生成轻量级运行时引擎
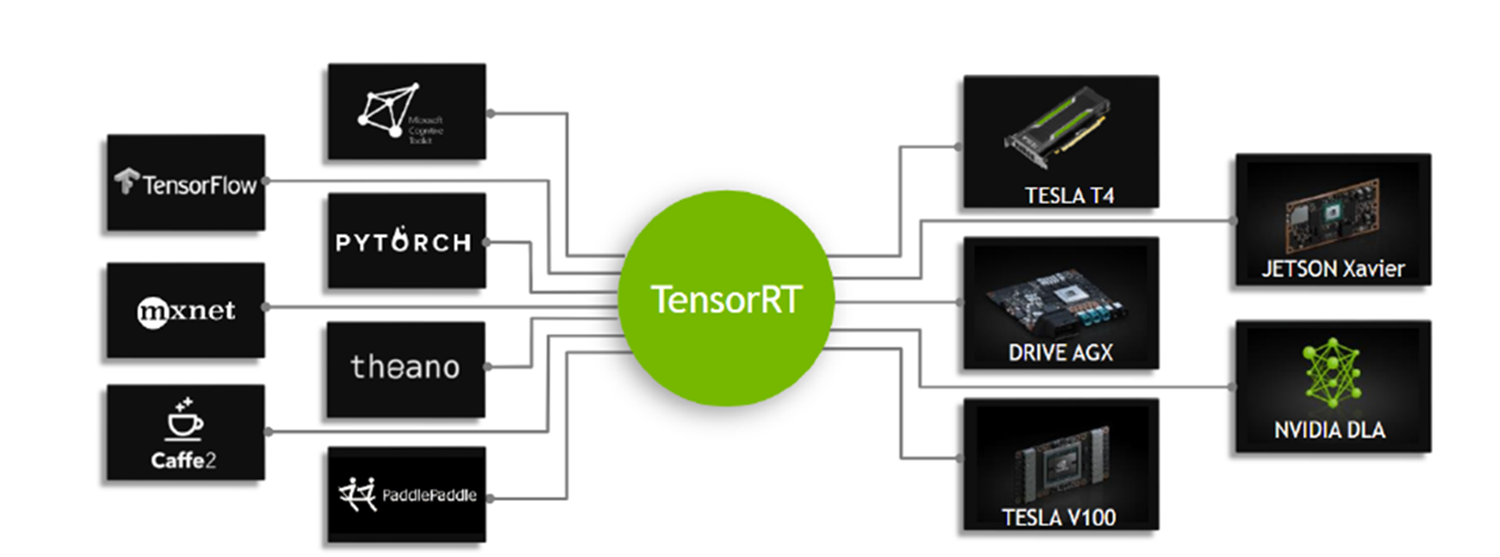
1.1 Benefits of TensorRT
-
→ 吞吐量
推理量/秒 或 样本量/秒来衡量 -
效率
每单位功率提供的吞吐量,通常表示为性能/瓦特 -
延迟
执行推理的时间,通常以毫秒为单位 -
99%+ 准确率
训练的神经网络能够提供正确答案的能力 -
内存占用
在网络上进行推理需要保留的主机和设备内存取决于所使用的算法,这限制了网络和网络的哪些组合可以在给定的推理平台上运行
1.2 Who Can Benefit From TensorRT
-
机器人
-
自动驾驶
-
科学计算
-
深度学习训练和部署框架
TensorRT包含在几个流行的深度学习框架中,包括TensorFlow和MXNet ... -
视频分析
为数千个视频源组合在一起的数据中心提供复杂的视频分析解决方案 -
自动语音识别
TensorRT用于在小型桌面/桌面设备上提供语音识别功能。 小型设备支持有限的词汇表,云端设备可用词汇量较大的词汇识别系统
1.3 Where Does TensorRT Fit?
通常,开发和部署深度学习模型的工作流程分为三个阶段
- 1.训练 TensorRT通常在训练阶段的任何部分都不使用
- 2.部署方案 以序列化格式写出推理引擎 (Plan File)
- 3.部署 在云端部署(TensorRT Inference Server),嵌入式系统
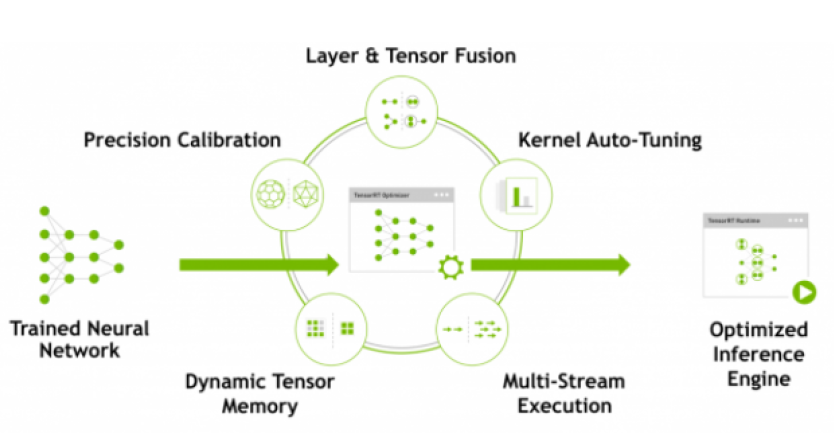
1.4 How Does TensorRT Work?
为了优化推理模型,TensorRT采用训练的网络定义,执行优化,包括特定于平台的优化,并生成推理引擎。此过程称为构建阶段(build phase)。构建阶段可能需要相当长的时间,尤其是在嵌入式平台上运行时。因此,典型的应用程序将构建一次引擎,然后将其序列化为计划文件(plan file)以供以后使用。
1.4 How Does TensorRT Work? (cont.)
- 生成的计划文件不能跨平台或TensorRT版本移植。计划特定于他们构建的确切GPU模型(除了平台和TensorRT版本)并且必须重新定位到特定GPU,以防您想在不同的GPU上运行它们。
-
构建阶段在图层上执行以下优化:
- 消除未使用输出的层;
- 融合卷积、偏差和ReLU操作;
- 聚合足够相似的参数和相同的源张量的操作(例如,GoogleNet v5 inception模块中的1x1卷积);
- 通过将层输出定向到正确的最终目标来合并连接层。
- 如有必要,builder还会会修改权重的精度
- 构建阶段还在虚拟数据上运行图层以从其内核目录中选择最快的内核,并在适当的情况下执行权重预格式化和内存优化
1.5 What Capabilities Does TensorRT Provide?
TensorRT使开发人员能够导入、校准、生成和部署优化网络。网络可以直接从Caffe导入,也可以通过UFF或ONNX格式从其他框架导入。它们也可以通过实例化单个图层并直接设置参数和权重来以编程的方式创建。
用户还可以使用Plugin界面通过TensorRT运行自定义图层。通过graphurgeon实用程序,可以将TensorFlow节点映射到TensorRT中的自定义层,从而可以使用TensorRT对许多TensorFlow网络进行推理。
TensorRT在所有支持的平台上提供C ++实现,在x86上提供Python实现。
TensorRT核心库中的关键接口 (1.5 cont.)
- 网络定义: 可以参考网络定义API
- 编译器: Builder允许从网络定义创建优化引擎,它允许应用程序指定最大批次和工作空间大小,最低可接受的精度水平,计时迭代计算的自动剪枝优化,以及用于量化网络以8位精度运行的接口。有关Builder的更多信息,请参阅Builder API
- 引擎: Engine接口允许应用程序执行推理。它支持同步和异步执行、分析、枚举和查询引擎输入和输出的绑定。单个引擎可以具有多个执行上下文,允许使用单组训练参数来同时执行多个批次。有关Engine的更多信息,请参阅Execution API
TensorRT提供解析器,用于导入经过训练的网络以创建网络定义 (1.5 cont.)
- caffe解析器: 此解析器可用于解析在BVLC Caffe或NVCaffe 0.16中创建的Caffe网络。它还提供了为自定义图层注册插件工厂的功能。有关C ++ Caffe Parser的更多详细信息,请参阅NvCaffeParser 或Python Caffe Parser
- UFF解析器: 此解析器可用于以UFF格式解析网络。它还提供了注册插件工厂和传递自定义图层的字段属性的功能。有关C ++ UFF Parser的更多详细信息,请参阅 NvUffParser 或Python UFF Parser
- ONNX解析器: 此解析器可用于解析ONNX模型。有关C ++ ONNX Parser的更多详细信息,请参阅NvONNXParser 或Python ONNX Parser
2. How Do I Get TensorRT?
2.1 安装前的说明
- zip windows安装包暂时不支持Python,将来可能会支持
- 如果你使用Python API请安装PyCUDA,可以参考后文中的PyCUDA的安装
- 目前最新的TensorRT Release为: TensorRT Release 7.x.x
- CUDA的版本支持9.0, 10.0, 10.2
- 最新的TensorRT支持TensorFlow 1.15.0; Pytorch已经在1.3.0上测试,可能也支持更老的版本
- 最好保证训练的环境和模型转换的环境是一致的比如CUDA和cuDNN的版本一致性
- 只介绍.tar安装包的安装方式和PyCUDA的安装,其他安装方式包括:Debian, RPM,Zip等可参考官方文档
2.2 Tar File Installation
- 安装依赖环境
- CUDA 9.0, 10.0, or 10.2
- cuDNN 7.6.5
- Python 2 or Python 3 (Optional)
- 下载TensorRT tar文件
- 访问:https://developer.nvidia.com/tensorrt
- 选择TensorRT版本并下载
- 选择安装的文件夹,所有的安装文件最终都安装在以TensorRT-version对应的子文件夹中
2.2 Tar File Installation (cont.)
- 4.解压tar文件
$ tar xzvf TensorRT-${version}.${os}.${arch}-gnu.${cuda}.${cudnn}.tar.gz解压后会有 lib, include, data, etc… - 5.添加环境变量
$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:TensorRT-${version}/lib - 6.安装Python的TensorRT包
$ sudo pip3 install tensorrt-*-cp3x-none-linux_x86_64.whl
2.2 Tar File Installation (cont.)
- 7.安装Python UFF包(如果你打算在TensorFlow中使用TensorRT)
$ cd TensorRT-${version}/uff $ sudo pip3 install uff-0.6.5-py2.py3-none-any.whl - 8.安装Python graphsurgeon
$ cd TensorRT-${version}/graphsurgeon $ sudo pip3 install graphsurgeon-0.4.1-py2.py3-none-any.whl - 9.验证安装是否成功:运行samples/python下的例子,看是否安装成功!
$ cd amples/python/end_to_end_tensorflow_mnist $ python3 models.py $ cd /home/myuser/TensorRT-7.0.0.11/data $ python3 download_pgms.py $ python3 smaples.py -d /home/myuser/TensorRT-7.0.0.11/data
2.3 安装PyCUDA
PyCUDA是Python使用NVIDIA CUDA的API,在Python中映射了所有CUDA的API
安装:
$ pip3 install 'pycuda>=2019.1.1'
3. Working with TensorRT Using the Python API
3.1 Python API vs C++ API
从本质上讲,C ++ API和Python API在支持的需求方面应该完全相同。 Python API的主要优点是数据预处理和后处理易于使用,因为可以使用各种库,如NumPy和SciPy。
C ++ API应该用于安全性很重要的情况,例如汽车行业。有关C ++ API的更多信息,请参阅官方文档使用TensorRT的C ++ API。
- 从模型中创建TensorRT网络定义;
- 调用TensorRT builder以从网络创建优化的运行时引擎;
- 序列化和反序列化引擎,以便在运行时快速重新创建;
- 向引擎填充数据,执行推理。
3.2 在python中导入TensorRT
1.导入TensorRT
>>> import tensorrt as trt
2.实现日志记录接口,TensorRT通过该接口报告错误、警告和信息性消息。以下代码显示了如何实现日志记录接口。在这种情况下,我们已经抑制了信息性消息,并仅报告警告和错误。TensorRT Python绑定中包含一个简单的记录器。
>>> TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
3.3 在Python中创建网络定义
-
使用TensorRT进行推理的第一步是从您的模型创建TensorRT网络。实现此目的的最简单方法是使用TensorRT解析器库导入模型,支持以下格式的序列化模型:
- Caffe (both BVLC and NVCaffe);
- ONNX;
- UFF (used for TensorFlow)
- 另一种方法是使用TensorRT Network API直接定义模型,这要求您进行少量API调用以定义网络图中的每个层,并为模型的训练参数实现自己的导入机制
- TensorRT Python API仅适用于x86_64平台。有关详细信息,请参阅Deep Learning SDK文档 - TensorRT工作流程。
3.3.1 使用python API从头定义网络
构建网络时,必须首先定义引擎并为推理创建builder对象。Python API用于从Network API创建网络和引擎。网络定义参考用于向网络添加各种层。有关使用Python API创建网络和引擎的更多信息,请参阅network_api_pyt
>>> import tensorrt as trt
以下代码说明了如何使用Input,Convolution,Pooling,FullyConnected,Activation和SoftMax层创建简单网络。
# Create the builder and network
with trt.Builder(TRT_LOGGER) as builder, builder.create_network() as network:
# Configure the network layers based on the weights provided. In this case, the
weights are imported from a pytorch model.
# Add an input layer. The name is a string, dtype is a TensorRT dtype, and the
shape can be provided as either a list or tuple.
input_tensor = network.add_input(name=INPUT_NAME, dtype=trt.float32,
shape=INPUT_SHAPE)
# Add a convolution layer
conv1_w = weights['conv1.weight'].numpy()
conv1_b = weights['conv1.bias'].numpy()
conv1 = network.add_convolution(input=input_tensor, num_output_maps=20,
kernel_shape=(5, 5), kernel=conv1_w, bias=conv1_b)
conv1.stride = (1, 1)
pool1 = network.add_pooling(input=conv1.get_output(0),
type=trt.PoolingType.MAX, window_size=(2, 2))
pool1.stride = (2, 2)
conv2_w = weights['conv2.weight'].numpy()
conv2_b = weights['conv2.bias'].numpy()
conv2 = network.add_convolution(pool1.get_output(0), 50, (5, 5), conv2_w,
conv2_b)
conv2.stride = (1, 1)
pool2 = network.add_pooling(conv2.get_output(0), trt.PoolingType.MAX, (2, 2))
pool2.stride = (2, 2)
fc1_w = weights['fc1.weight'].numpy()
fc1_b = weights['fc1.bias'].numpy()
fc1 = network.add_fully_connected(input=pool2.get_output(0), num_outputs=500,
kernel=fc1_w, bias=fc1_b)
relu1 = network.add_activation(fc1.get_output(0), trt.ActivationType.RELU)
fc2_w = weights['fc2.weight'].numpy()
fc2_b = weights['fc2.bias'].numpy()
fc2 = network.add_fully_connected(relu1.get_output(0), OUTPUT_SIZE, fc2_w,
fc2_b)
fc2.get_output(0).name =OUTPUT_NAME
network.mark_output(fc2.get_output(0))
3.3.2 使用Python中的Parser导入模型
要使用解析器导入模型,您需要执行以下步骤:
- 创建TensorRT builder和network;
- 为特定格式创建TensorRT解析器;
- 使用解析器解析导入的模型并填充网络。
不同的解析器具有用于标记网络输出的不同机制。具体可参考 UFF Parser API ,Caffe Parser API, and ONNX Parser API,这里我们只介绍UFF Parser,并且将在Section 4的例子中介绍Darknet版本的YOLO v3以及TensorFlow版本的ResNet50如何通过UFF Parser API进行加速推断
3.3.3 使用Python接口导入Tensorflow模型
以下步骤说明了如何使用UFFParser和Python API直接导入TensorFlow模型。此示例可以在 / tensorrt / samples / python / end_to_end_tensorflow_mnist目录中找到。有关更多信息,请参阅end_to_end_tensorflow_mnist Python示例(我们同时使用该示例验证TensorRT的安装)。
- 1.导入TensorRT
>>> import tensorrt as trt
- 2.创建冻结的TensorFlow模型
- 3.使用UFF转换器将冻结的Tensorflow模型转换为UFF文件
$ convert-to-uff frozen_inference_graph.pb
3.3.3 使用Python接口导入Tensorflow模型(cont.)
- 4.定义路径。更改以下路径以反映Samples中包含的模型的位置
>>> model_file = '/data/mnist/mnist.uff'
- 5.创建builder,network和parser:
with builder = trt.Builder(TRT_LOGGER) as builder, builder.create_network() as network, trt.UffParser() as parser: parser.register_input("Placeholder", (1, 28, 28)) parser.register_output("fc2/Relu") parser.parse(model_file, network)
导入Caffe,ONNX,Pytorch框架的模型类似,可参考官网介绍
3.4 使用Python接口创建引擎
- builder的一个功能是搜索其CUDA内核目录以获得最快的可用实现,因此必须使用相同的GPU来构建优化引擎将运行的GPU
- builder具有许多属性,可以设置这些属性以控制网络应运行的精度,以及自动调整参数,例如TensorRT在确定哪个最快时(多次迭代导致更长的运行时间)应该为每个内核计时多少次同时对噪声的敏感性较低)。还可以查询builder以找出硬件本身支持的混合精度类型。
- 两个特别重要的属性是最大batch大小和最大workspace大小
- 最大batch大小指定TensorRT将优化的批量大小。在运行时,可以选择较小的批量大小;
- 层算法通常需要临时工作空间。此参数限制网络中任何层可以使用的最大大小。如果提供的scratch不足,则TensorRT可能无法找到给定层的实现;
- 有关使用Python构建引擎的更多信息,请参阅introduction_orySamples示例
3.4 使用Python接口创建引擎(cont.)
1.使用builder对象创建引擎:
builder.max_batch_size = max_batch_size
builder.max_workspace_size = 1 << 20 # This determines the amount of memory available to the builder when building an optimized engine and should generally be set as high as possible.
with trt.Builder(TRT_LOGGER) as builder:
with builder.build_cuda_engine(network) as engine:
# Do inference here.
在构建引擎时,TensorRT会复制权重
2.进行推理
3.5 在Python中序列化引擎
序列化时,将引擎转换为一种格式,以便以后存储和使用以进行推理。要用于推理,只需反序列化引擎即可。序列化和反序列化是可选的。由于从网络定义创建引擎可能非常耗时,因此每次应用程序重新运行时都可以通过序列化一次并在推理时对其进行反序列化来避免重建引擎。因此,在构建引擎之后,用户通常希望将其序列化以供以后使用。
可以序列化引擎,也可以直接使用引擎进行推理。在将模型用于推理之前,序列化和反序列化是一个可选步骤 - 如果需要,可以直接使用引擎对象进行推理。
序列化引擎不能跨平台或TensorRT版本移植。引擎特定于它们构建的精确GPU模型(包括平台和TensorRT版本)。
3.5 在Python中序列化引擎(cont.)
1.序列化模型为modelstream:
serialized_engine = engine.serialize()
2.反序列化模型流以执行推理。反序列化需要创建运行时对象:
with trt.Runtime(TRT_LOGGER) as runtime:
engine = runtime.deserialize_cuda_engine(serialized_engine)
3.5 在Python中序列化引擎(cont.)
也可以将序列化引擎保存到文件中,并从文件中读回:
1.序列化引擎并写入文件:
with open(“sample.engine”, “wb”) as f:
f.write(engine.serialize())
2.从文件读取引擎并反序列化:
with open(“sample.engine”, “rb”) as f, trt.Runtime(TRT_LOGGER) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
3.6 使用Python接口执行推理
以下步骤说明了如何在Python中执行推理,现在已拥有引擎。
1.为输入和输出分配一些主机和设备缓冲区:
# Determine dimensions and create page-locked memory buffers (i.e. won't be swapped to disk) to hold host inputs/outputs. h_input = cuda.pagelocked_empty(engine.get_binding_shape(0).volume(),dtype=np.float32) h_output = cuda.pagelocked_empty(engine.get_binding_shape(1).volume(),dtype=np.float32) # Allocate device memory for inputs and outputs. d_input = cuda.mem_alloc(h_input.nbytes) d_output = cuda.mem_alloc(h_output.nbytes) # Create a stream in which to copy inputs/outputs and run inference. stream = cuda.Stream()
3.6 使用Python接口执行推理(cont.)
2.创建一些空间来存储中间激活值。由于引擎保持网络定义和训练的参数,因此需要额外的空间。它们保存在执行上下文中:
with engine.create_execution_context() as context:
# Transfer input data to the GPU.
cuda.memcpy_htod_async(d_input, h_input, stream)
# Run inference.
context.execute_async(bindings=[int(d_input), int(d_output)],stream_handle=stream.handle)
# Transfer predictions back from the GPU.
cuda.memcpy_dtoh_async(h_output, d_output, stream)
# Synchronize the stream
stream.synchronize()
# Return the host output.
return h_output
引擎可以具有多个执行上下文,允许一组权重用于多个重叠推理任务。例如,可以使用一个引擎和每个流中各一个上下文在并行CUDA流中处理图像。每个上下文将在与引擎相同的GPU上创建。
4. An Object Detection Model: YOLO v3 with TensorRT (Example 1)
4.1 为什么选择YOLO v3测试
- 1. 传统的特征提取,two-stage, one-stage,anchor-free,基于NAS的网络搜索(EfficientDet)
- 2. YOLO v3在业界应用较多(很好的权衡了速度和精度)
- 3. YOLO系列的改进模型较多YOLO-tiny, YOLO-SPP, Gaussian-YOLO, GIoU-YOLO, D/CIoU-YOLO, etc.

4.2 Darknet,TensorFlow,TensorRT的PK
- DarkNet: Darknet版本的YOLO v3
- TensorFlow: Darknet版本转化为TensorFlow版本基于TensorFlow测试
- TensorRT: 基于UFFParser(TensorRT并不支持所有的TensorFlow API)
- TensorRT: Darknet转化为ONNX,基于ONNXParser,但是仍然只是加速了卷积不部分
- TensorFlow 1.9.0 + TensorRT 4(基于TensorFlow集成的TensorRT可以加速)
YOLO v3推断速度测试
-
Darknet
-
TensorFlow
-
TensorRT
5. A Classification Model: ResNet50 with TensorRT (Example 2)
5.1. 项目的文件结构
02_ResNet50_UFF # 项目根目录
│ ckpt2pb.py # ckpt文件转化为pb文件
│ class_labels.txt # imagenet类别label
│ README.md # readme
│ requirements.txt # 需要安装的包
│ ResNet50_pb.py # tensorflow推断
│ ResNet50_UFF.py # tensorRT 推断
│ see_graph_node.py # 查看pb文件的node
│ WORKSPACE # bazel workspace
│
├─model # 需要的模型
│ frozen_resnet_v1_50.pb # tensorflow pb model
│ frozen_resnet_v1_50.uff # TensorRT UFFPaser model
│ resnet_v1_50.ckpt # tensorflow ckpt
│
├─nets # ResNet50的网络结构定义
│ nets_factory.py
│ resnet_utils.py
│ resnet_v1.py
│
└─test_img # 测试图片
binoculars.jpeg
reflex_camera.jpeg
tabby_tiger_cat.jpg
5.2 TensorRT与Tensorflow推断速度的测试过程
- 1.训练模型: ResNet_v1_50
- 2.冻结模型:
这一步将一些训练好的模型变量存储为常量,并冻结图结构,如果不使用TensorRT,该模型将作为最终的上线模型,这里多数一句TensorFlow Serving部署的模型及tflite移动端部署的模型保存方式都是不同的!
- 导出推断的图结构
python3 ckpt2pb.py --alsologtostderr --model_name=resnet_v1_50 --output_file=./model/resnet_v1_50_inf_graph.pb
- 冻结图结构
# 查看输出节点信息 python3 see_graph_node.py # 冻结模型 freeze_graph \ --input_graph=./model/resnet_v1_50_inf_graph.pb \ --input_checkpoint=./model/resnet_v1_50.ckpt \ --input_binary=true --output_graph=./model/frozen_resnet_v1_50.pb \ --output_node_names=resnet_v1_50/predictions/Reshape_1
- 导出推断的图结构
5.2 TensorRT与Tensorflow推断速度的测试过程(cont.)
- 3.将冻结的模型转化为TensorRT所用的uff模型
convert-to-uff ./model/./model/frozen_resnet_v1_50.pb
Using output node resnet_v1_50/predictions/Reshape_1 Converting to UFF graph Warning: keepdims is ignored by the UFF Parser and defaults to True DEBUG [/usr/local/lib/python3.5/dist-packages/uff/converters/tensorflow/converter.py:96] Marking ['resnet_v1_50/predictions/Reshape_1'] as outputs No. nodes: 453 UFF Output written to ./model/frozen_resnet_v1_50.uff
5.2 TensorRT与Tensorflow推断速度的测试过程(cont.)
- 4.推断
- TensorRT:
# 测试的GPU为Tesla V100 32G现存 python3 ResNet50_UFF.py
- Tensorflow:
python3 ResNet50_pb.py
- TensorRT:
5.3 推断结果和速度对比
binoculars.jpg
- TensorRT 预测结果:binoculars,推断时间:0.00360s
- TensorFlow 预测结果:binoculars, 推断时间:3.51410s

5.3 推断结果和速度对比(cont.)
reflex_camera.jpg
- TensorRT 预测结果:reflex camera,推断时间:0.00413s
- TensorFlow 预测结果:reflex camera, 推断时间:0.00674s

5.3 推断结果和速度对比(cont.)
tabby_tiger_cat.jpg
- TensorRT 预测结果:tabby,推断时间:0.00345s
- TensorFlow 预测结果:tabby, 推断时间:0.00685s
