seq2seq介绍
1.简单介绍
Seq2Seq技术,全称Sequence to Sequence,该技术突破了传统的固定大小输入问题框架,开通了将经典深度神经网络模型(DNNs)运用于在翻译,文本自动摘要和机器人自动问答以及一些回归预测任务上,并被证实在英语-法语翻译、英语-德语翻译以及人机短问快答的应用中有着不俗的表现。
2.模型的提出
提出:Seq2Seq被提出于2014年,最早由两篇文章独立地阐述了它主要思想,分别是Google Brain团队的《Sequence to Sequence Learning with Neural Networks》和Yoshua Bengio团队的《Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation》。这两篇文章针对机器翻译的问题不谋而合地提出了相似的解决思路,Seq2Seq由此产生。
3.核心思想
Seq2Seq解决问题的主要思路是通过深度神经网络模型(常用的是LSTM,长短记忆网络,一种循环神经网络)http://dataxujing.coding.me/深度学习之RNN/。将一个作为输入的序列映射为一个作为输出的序列,这一过程由编码(Encoder)输入与解码(Decoder)输出两个环节组成, 前者负责把序列编码成一个固定长度的向量,这个向量作为输入传给后者,输出可变长度的向量。
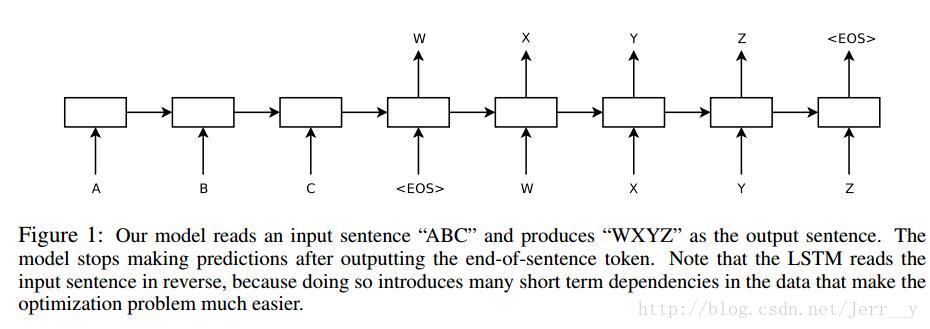
图1:Seq2Seq示意图
由上图所示,在这个模型中每一时间的输入和输出是不一样的,比如对于序列数据就是将序列项依次传入,每个序列项再对应不同的输出。比如说我们现在有序列“A B C EOS” (其中EOS=End of Sentence,句末标识符)作为输入,那么我们的目的就是将“A”,“B”,“C”,“EOS”依次传入模型后,把其映射为序列“W X Y Z EOS”作为输出。
4.模型应用
seq2seq其实可以用在很多地方,比如机器翻译,自动对话机器人,文档摘要自动生成,图片描述自动生成。比如Google就基于seq2seq开发了一个对话模型[5],和论文[1,2]的思路基本是一致的,使用两个LSTM的结构,LSTM1将输入的对话编码成一个固定长度的实数向量,LSTM2根据这个向量不停地预测后面的输出(解码)。只是在对话模型中,使用的语料是((input)你说的话-我答的话(input))这种类型的pairs 。而在机器翻译中使用的语料是(hello-你好)这样的pairs。
此外,如果我们的输入是图片,输出是对图片的描述,用这样的方式来训练的话就能够完成图片描述的任务。等等,等等。
可以看出来,seq2seq具有非常广泛的应用场景,而且效果也是非常强大。同时,因为是端到端的模型(大部分的深度模型都是端到端的),它减少了很多人工处理和规则制定的步骤。在 Encoder-Decoder 的基础上,人们又引入了attention mechanism等技术,使得这些深度方法在各个任务上表现更加突出。
5.Paper
首先介绍几篇比较重要的 seq2seq 相关的论文:
[2] Sutskever et al., 2014. Sequence to Sequence Learning with Neural Networks.
[3] Bahdanau et al., 2014. Neural Machine Translation by Jointly Learning to Align and Translate.
[4] Jean et. al., 2014. On Using Very Large Target Vocabulary for Neural Machine Translation.
[5] Vinyals et. al., 2015. A Neural Conversational Model. Computer Science.